|
Las enseñanzas del Maestro Ciruela
El índice de abuelidad
QUÉ ES EL ÍNDICE DE ABUELIDAD
Es un número entre 0 y 1 que nos indica cuál es la probabilidad de que una persona (llamémosla Mengano) sea la nieta biológica de otra (que será Gertrudis).
Ese número se interpreta de la siguiente manera: si es 1 indica la certeza absoluta, o sea, Mengano es nieto biológico de Gertrudis sin lugar a dudas. El 1 nunca se alcanza.
Si el número es 0 (cero) indica que no es posible, de ninguna manera, que Mengano sea nieto biológico de Gertrudis.
Si es un número intermedio, cuanto más cercano a 1 se halle mayor es la probabilidad de de Mengano sea nieto biológico de Gertrudis. Y cuanto más cercano a 0 menor es esta probabilidad. Un índice de 0,50 nos estaría diciendo de que existe un 50% de probabilidades de que Mengano sea nieto de Gertrudis y un 50% de que no lo sea.
Es imposible obtener la certeza absoluta, el 1. No por impericia o por falta de recursos. Es imposible por las leyes de la naturaleza. En cambio, sí es posible obtener el 0, o sea, la certeza absoluta acerca de la no relación biológica entre Gertrudis y Mengano.
Supongamos que sabemos que Mengano es efectivamente el nieto de Gertrudis, entonces, al aplicar el índice de abuelidad podríamos obtener números como 0,999, o 0,999941, o cosas por el estilo, dependiendo un poco del azar, otro poco de la cantidad y calidad de los marcadores que utilicen los técnicos (ya te explico qué son los marcadores) y otro poco de la cantidad de parientes presuntos de los que podamos extraer material biológico para comparar.
Lo mismo que te estoy contando para determinar la abuelidad vale para la paternidad; funciona de la misma manera. En los litigios judiciales, los jueces utilizan el índice de abuelidad para dictaminar sobre la filiación de una persona y, en tal caso, restituirlo a su familia biológica y devolverle la identidad al nieto. Pero para hacerlo cuentan no sólo con el índice de abuelidad sino también con un gran número de evidencias fácticas y pruebas, o sea, una evaluación pericial completa (quién aduce que Mengano sea su hijo, dónde y cómo nació Mengano, qué dice su certificado de nacimiento, quiénes son testigos de ese embarazo y nacimiento y qué cuentan y decenas de etcéteras) de modo tal que al sentenciar puede hacerlo con plena certeza.
QUÉ SON LOS MARCADORES
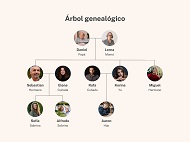
Los marcadores o, mejor aún, los marcadores genéticos, son las secuencias genéticas que sirven para trazar una historia familiar (un árbol genealógico o pedigree) del tipo: Mengano es hijo de Rubén y de Diana, que a su vez es hija de Ramón y Gertrudis, que a su vez es hija de Francisco y... y así.
Hasta no hace mucho tiempo era imposible leer las secuencias genéticas, pero podíamos observar sus productos. Pongamos un ejemplo: sabemos que el color de los ojos depende de un gen, o sea, una secuencia de ADN particular (los genes son estructuras químicas compuestas por secuencias de nucleótidos, donde cada uno funge como letras en un renglón sin espacios en blanco; hay solo cuatro letras que llamamos A, T, G y C). En nuestros cromosomas hay genes que son instrucciones para fabricar todos nuestros componentes corporales. Y uno de ellos fabrica el iris de nuestros ojos. Pero en la población humana hay dos tipos (en realidad hay más, pero estoy simplificando la cuestión), dos versiones de este gen: la que fabrica iris celestes y la que fabrica iris marrones. Y dependiendo de las versiones que tengamos en nuestros genomas será el color de nuestros ojos.
Pero hay una complicación más. Nuestros genomas están (casi en su totalidad) duplicados, ya que recibimos un juego de genes de nuestro padre y otro juego de nuestra madre. De modo que podemos tener dos genes para celeste, dos genes para marrón, o uno para cada color. Cuando los dos genes son del mismo tipo no hay duda, de ese color serán nuestros ojos. Y si tenemos un gen para cada color tendremos ojos marrones (existe lo que llamamos dominancia entre genes, pero que a los fines de este ejemplo no tiene importancia).
La cuestión es que entonces, el color de ojos puede revelar algo sobre la filiación de las personas, o sea, ser un marcador. Si los ambos padres tienen ojos celestes, entonces todos sus hijos deben tener ojos celestes. Y si tuviesen un hijo de ojos marrones sabríamos sin lugar a dudas que no es hijo biológico de esa pareja. Por otro lado, el hecho que un hijo tenga ojos celestes no es garantía de que sea hijo biológico de esa pareja, no necesito explicarlo, ya que podría ser hijo de muchísimas personas diferentes y portadoras del gen para ojos celestes. La probabilidad de ese hecho sólo dependería de cuán representado esté el gen para ojos celestes en el acervo genético de la población.
Acá ya aparece la característica de la certeza para la exclusión y apenas una probabilidad para la inclusión, como anticipé más arriba.
Pero ahora supongamos que existe una variante rarísima de gen para color de ojos cuya presencia en el genoma aún en copia única da ojos verde amarillentos con pintitas rojas. Y que nace un niño con esos ojos locos en una familia de padres con ojos celestes que viven en un vecindario en el que trabaja el diarero que tiene ojos verde amarillentos con pintitas rojas. Si este buen hombre quisiese dar su apellido al niño tendría que plantear un juicio de filiación y los genetistas tendrían que sacarle punta al lápiz para obtener un índice de paternidad. El índice de paternidad daría un número bastante cercano a 1. El diarero podría andar diciendo por ahí: el pibe lleva mi firma.
Cuanto más representado aparezca un tipo (o variante, o versión) de un gen en la población (frecuencia alta), peor marcador será. Cuanto más rara sea una versión (frecuencia baja), mejor marcador será.
A su vez, cuantas más versiones existan para un mismo gen, mejor marcador será (lo que llamamos un marcador polimórfico).
Otros marcadores mucho más precisos que el gen para el color de ojos y que se utilizaron con mucho éxito antes de que se pudiese secuenciar el ADN de nuestros genomas son: el sistema de grupos sanguíneos (AB0, rh+/-) y el sistema de antígenos leucocitarios humanos (HLA, o sistema de histocompatibilidad, que se utiliza para saber si un trasplante va a ser aceptado).
También interviene el azar, porque, por ejemplo, si estamos trabajando sobre el sistema sanguíneo como marcador y el sujeto objetivo pertenece al grupo 0+ estamos en el horno, la mitad de la población argentina pertenece a ese grupo. Pero si en cambio el sujeto pertenece al grupo AB- (menos del 1% de los argentinos pertenece a este grupo) el índice obtenido será un número mucho más cercano a 1; o será 0, por supuesto.
Y también, cuantos más marcadores se evalúen para un mismo análisis de filiación, mejor será el análisis. Por ejemplo, considerando el sistema sanguíneo más el sistema de histocompatibilidad obtenemos mejores resultados. O sea: más cercano a 1 será el índice si hay parentesco verdadero, o más fácil es que se obtenga un 0 si no hay parentesco.
LOS MARCADORES DE SECUENCIAS
En cuanto la técnica de secuenciar el ADN (o sea: leer la secuencia de letras A, T, G y C) se hizo razonablemente alcanzable, se vio que eligiendo correctamente qué segmentos de ADN secuenciar, esas lecturas se convertían en unos marcadores excelentes.
Y qué segmentos elegir. En cada una de nuestras células tenemos 46 cromosomas, que no son otra cosa que larguísimas tiras de ADN. La cantidad total de nucleótidos (o sea letras) que hay sumando los 46 cromosomas es de 6.400 millones. No toda la secuencia tiene información para fabricar proteínas (o sea los componentes del cuerpo), sino sólo el 30%. En el restante 70%, que no contiene genes, hay de todo: algunas secuencias tienen funciones regulatorias, otras no sabemos si tienen alguna función y otras son decididamente basura acumulada durante 3.000 millones de años.
Esta última, la de la basura, es la mejor parte donde buscar marcadores de filiación. El motivo es que pueden variar de una generación a otra sin comprometer la viabilidad del nuevo ser, de modo que la variación perdure en el tiempo. A estas variaciones las llamamos mutaciones y pueden ocurrir por varios motivos, pero el más frecuente es por un error en la replicación del ADN cuando se fabrican las gametas (óvulos y espermatozoides). Si un error de replicación afectase a un gen sería raro que el engendro resultase viable, aunque podría ocurrir (es, por ejemplo, el caso del color de los ojos). Las mutaciones en las zonas codificantes –o sea, dentro de los genes– no sólo deben pasar ese primer filtro de no ser abortivos, también deben otorgar cierta competitividad para no quedar condenadas al olvido y la extinción. Los biólogos decimos: “son mutaciones sometidas a la presión evolutiva”. En cambio, las mutaciones en el ADN no codificante (más precisamente en el sector basura) al no estar sometidas a esa presión selectiva se convierten en regiones hipervariables excelentes para buscar marcadores. Toda mutación en esa región se eterniza.
Unos marcadores muy utilizados son los “microsatélites” (SSR o STR por sus acrónimos en inglés para simple sequence repeat y short tandem repeat). Se las llamó así a unas regiones que contenían gran cantidad de repeticiones de tándems de letras, por ejemplo: CTAT n veces. Existen decenas de regiones perfectamente caracterizadas en las que se vio que la cantidad de repeticiones: 3, 6, 7, 20, las que sean, constituyen excelentes marcadores de pertenencia a un linaje familiar, a una progenie. Además, en una población suelen estar representadas casi todas las longitudes (repeticiones del tándem) o sea, son altamente polimórficas. Por otro lado, como existen muchos sitios STR, al analizarlos en conjunto, se logra una huella digital genética tal que es enormemente improbable que otro individuo, tomado al azar, la posea. Como la huella digital.
En una identificación genética se utilizan 16 (y hasta 21) STRs, lo que nos da una probabilidad de 0,000.000.000.000.000.001 de que exista otro individuo –tomado al azar– con la misma huella genética (uno en un trillón, que son muchos más de los que habitan el planeta).
El ADN mitocondrial (ADNmt)
Los microsatélites, que nos ocuparon en el bloque anterior, son parte de lo que se llama el ADN nuclear, debido a que es el que se encuentra en el núcleo de las células. Ahí se halla, empaquetado, en los 46 cromosomas. Pero de esos 46, 23 cromosomas los aportó un óvulo de la madre y 23, un espermatozoide del padre. Los 23 que aportó cada uno son casi idénticos a los 23 que aportó el otro. Nuestra información genética se halla por duplicado. En biología llamamos a este fenómeno diploidía, y decimos que nuestra información genética es diploide.
Esto agrega una cuota de complejidad si lo que queremos hacer con un marcador es trazar un parentesco ya que no toda la información genética de una persona aparecerá en su progenie, sino sólo la mitad. Y en una segunda generación, apenas un cuarto.
Pero existe ADN que sólo se hereda por parte de padre (a los hijos varones) o solo se hereda por parte de madre (a todos sus hijos independientemente de su sexo). Estos ADN pasan de generación en generación representados al ciento por ciento sin mezclarse con los del otro progenitor, de modo que “viajan” en el tiempo, generación tras generación sin alterarse en lo más mínimo y permiten rastrear linajes por cientos de años... también por miles de años... también por cientos de miles de años.
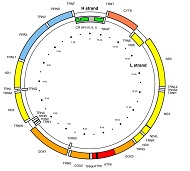
El que heredan los varones de su padre es el cromosoma Y. Y el ADN que se hereda de la madre no es nuclear, no viene de uno de los 46 cromosomas. Es un ADN que se halla fuera del núcleo de las células, en su citoplasma, dentro de unas pequeñas organelas llamadas mitocondrias. Resulta que en cada célula hay cientos de mitocondrias, y por suerte son todas iguales, como una colonia. Ese ADN proviene exclusivamente de nuestra madre (o sea, jerga: no es diploide, es haploide). Y cada mitocondria posee un pequeño cromosoma circular de 16.569 nucleótidos (200 mil veces más pequeño que el ADN nuclear), con información para 37 genes. Éste ADN recibe el nombre de ADN mitocondrial (ADNmt).
El ADNmt también contiene tres regiones hipervariables que no codifican para ningún gen, llamadas HV1, HV2 y HV3 que suman un total de entre 600 y 800 nucleótidos y en las que podemos hallar numerosos marcadores, generalmente mutaciones puntuales (o sea, un cambio de una sola letra, por ejemplo ...ATTCGT... por ...ATCCGT...)
Los genetistas proceden de la siguiente manera: construyen lo que se llama un “genotipo consenso” del ADNmt, con la secuencia de letras abrumadoramente mayoritarias para cada posición en la secuencia del genoma. Y lo comparan con la secuencia obtenida del ADNmt del sujeto que se está estudiando. Tomemos un ejemplo: acá aparece un segmento de 48 nucleótidos de la secuencia consenso (está inventado), el mismo segmento de ADNmt de Gertrudis, el mismo segmento de Mengano y el mismo segmento de Pedrito (otro nieto presunto). |